The Yellow Brick Road to Application Performance
Joel Goldstein
Tel. (732) 972-1261
Fax. (732) 972-9416
Buffer Pool Tool™ for DB2 The only product that can Predict the effect of changes to the buffer pools.
Coupling Facility Sizing Module Sizes the CF structures based on statistical data from your ‘operating’ DB2 system(s).
Are you still stuck in BP0? No installation should still be using only one pool! Even systems using as few as 6000 buffers can get better performance with the same memory across more than one pool! Proper sizing of the pools and placement of objects can provide dramatic application performance improvements. With the arrival of version 3, we went from an environment that was tunable, to infinite tuning possibilities. The most difficult part of the tuning process is determining which objects to place in a pool, and pool sizing to optimize performance. While general shotgun approaches, such as placing all indexes into one pool and sort/work into another, usually provide substantial gains, the scientific placement and optimization of pool sizes will provide major additional performance improvements. This article addresses all of these issues, as well as all the effects of the new alterable tuning thresholds with version 3. Before and after examples of tuning scenarios and the performance improvements from several installations are illustrated, as well as one installation that saved 144 Megabytes of memory while reducing average transaction elapsed times. The basic steps and necessary information for effectively tuning the pools are applicable to releases of DB2 prior to version 3 as well as version 4.1 and future releases.
DB2s Buffer Pools are the primary system tuning resource, and directly impact application response time and system I/O rates. Almost every installation should be using multiple pools, and using them effectively will optimize both the application performance and DB2s usage of memory resources. The only installations that should not use more than one pool are memory constrained and cannot afford to provide at least 5000 buffers to DB2.
The Past:
Prior to V3, we were quite limited in our tuning ability because we only had three 4K pools to separate the objects. Many installations maintained an erroneous assumption that they could get better performance with one large pool rather than multiple pools. Several studies showed that installations using as few as 6000 buffers, for BP0 (only), and one using only 5000 buffers, obtained markedly better performance when using at least two pools and the same number of buffers. Several major misconceptions exist regarding buffer pool performance, many of them fostered by inaccurate definitional information provided by online monitors and other documentation. The DWTH (deferred write threshold) is incremented in every system – however, in most cases this is really the VDWTH (vertical deferred write threshold) threshold at the object level that did not have its own counter prior to Version 3. Current Buffers Active (CBA) is shown in many monitors as ‘amount of pool in use’; this is incorrect, since 100% of the pool is always used. CBA is the amount of the pool that is ‘not available’ because the buffers contain updated and uncommitted data, or are currently having data read into them. A Getpage/Read I/O ratio is a very poor measure of pool efficiency. A true pool hit ratio provides a more accurate measurement and is covered later in this article.
The Present:
DB2 Version 3 and later releases provide 50-4K pools and 10-32K pools to tune the environments. The fact that IBM gave us this many pools should put to rest the misconception (that is still used in some IBM presentations) that one large pool is the best way to optimize overall performance. Naturally, every installation should start with one pool…and very quickly move to multiple pools to optimize performance and maximize DB2s use of memory. The dynamically adjustable thresholds (and pool sizes) have been sorely needed for many years. The default thresholds for the pools, as with most default values, are rarely correct for any installation. The first two that should be altered immediately are VWTH and DWTH. These should be set quite low to force updated page writes out of the system sooner, and avoid major performance hiccups at checkpoint intervals. While percentages vary based on number of buffers, a low percentage for VWTH, setting the number of buffers as close as possible to (but not less than)128, will optimize DB2s use of the asynchronous write facility. DWTH should be reduced into the range of 25%, as long as the number of buffers for the pool is 2000 or more. The VPSEQT (sequential threshold) should be set quite low for pools dedicated to objects accessed randomly, but never quite to zero. This allows some dynamic prefetch to occur without seriously impacting the base usage of the pool.
Buffer Pool Thresholds:
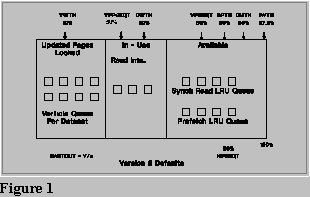 The pages in the left two sections of the pool illustration in Figure 1 are the current buffers active, or ‘CBA’ pages. DB2s usage of the two basic LRU queues is critical to overall pool performance. Now that the percentages of the pages used for each queue is adjustable, we have precise tuning ability. The ‘Free’ page queue is maintained only if HiperPools are in use, and can be used for pages being moved back from a hiperpool, or new pages being read into the pool from external storage. In either case, it is more efficient since pages will not have to be freed or stolen from the other two queues, or migrated to a HP to make room for the new pages. An additional threshold is the Virtual Pool Parallel Sequential Threshold, or VPPSEQT. This controls the number of buffers that can be used for parallel I/O streams. The VPPSEQT default threshold is 40% of whatever value the VPSEQT has…so if the pool has 10,000 buffers, and the VPSEQT is 80%, then the default 50% VPSEQT provides 4000 buffers. If Parallel I/O is not being used, the VPPSEQT does not matter…if you want to disable it, set VPPSEQT to 0%.
The pages in the left two sections of the pool illustration in Figure 1 are the current buffers active, or ‘CBA’ pages. DB2s usage of the two basic LRU queues is critical to overall pool performance. Now that the percentages of the pages used for each queue is adjustable, we have precise tuning ability. The ‘Free’ page queue is maintained only if HiperPools are in use, and can be used for pages being moved back from a hiperpool, or new pages being read into the pool from external storage. In either case, it is more efficient since pages will not have to be freed or stolen from the other two queues, or migrated to a HP to make room for the new pages. An additional threshold is the Virtual Pool Parallel Sequential Threshold, or VPPSEQT. This controls the number of buffers that can be used for parallel I/O streams. The VPPSEQT default threshold is 40% of whatever value the VPSEQT has…so if the pool has 10,000 buffers, and the VPSEQT is 80%, then the default 50% VPSEQT provides 4000 buffers. If Parallel I/O is not being used, the VPPSEQT does not matter…if you want to disable it, set VPPSEQT to 0%.
The HiperPool facility of V3 provides the ability to utilize ESO Hiperspaces as an extension of the Buffer Pools. When this facility is used, it provides almost (but not quite) identical performance to base pools adequately backed by central storage. The primary advantage to this approach, is the ability to keep large amounts of data in memory without driving up the MVS paging rate. Block migration of data to/from the HiperPool is handled by a new facility ‘ADMF’ (Asynchronous Data Mover Facility) that runs in SRB mode under the IOP engine rather than a central processor engine. This reduces the cost of data movement vs. MVS paging of a normal data page by approximately 8%.
Another reason to use this approach is the MVS limit of 2 Gigabytes for an Address Space – such as the DB2 Database Manager. While there is a maximum limit of 1.6 Gigabytes of ‘virtual’ buffer pool space that can be defined, using all of this will certainly cause this address space to hit the 2 Gigabyte limit when the EDM pool is added, and later the RID and Sort Work pools are added in dynamically. An additional threshold that must be considered by some large installations, is the limit of 10,000 open datasets for an address space. These are hard thresholds that cannot be exceeded. While HiperPools easily get us around the first two, the dataset limit has already become a problem for several large installations. When you reach this number of objects, deferred (slow) close must be implemented. These require a solid knowledge of the applications object usage patterns, since incorrectly using closerule ‘Y’ for many objects will generate cpu overhead for the Database Manager address space, and delay application performance/response times. DB2 V3 will also close datasets having closerule ‘N’ if DSMAX is exceeded and the datasets are not in use.
When HiperPools are used, DB2 creates and maintains an additional queue of ‘free pages’. This queue improves performance because a target page does not have to located from one of the normal LRU queues, and will not have to be migrated to the HP before a page is available for a new data page. DB2 attempts to maintain 128 or 256 pages in this free queue depending on the defined size of the virtual pool.
The application and system impact of good vs. poor buffer pool hit ratios are illustrated in Table 1. The only area of negative performance impact is the bottom line.
| Hit Ratio | Performance | ||
|---|---|---|---|
| Virtual Pool | HiperPool | CPU Cost | Elapsed Time |
| High | …. | Small | Reduced, Lower I/O |
| Low | High | Small | Reduced Lower I/O |
| Low | Low | increase | Increase |
While using hiperpools sounds like a real panacea, and does have major benefits, there is no ‘free lunch’ here. Implementing hiperpools still costs some space in the DBM1 (database manager) address space…about 2% of the defined hiperpool size. A 2-Gigabyte HP, requires about 40 megabytes of memory in the DBM1 address space for ‘Hash Blocks’ that contain information about all the pages that are in the HP. Additionally, the HP can be ‘Page Fixed’ in expanded by using CASTOUT=N. When this is not used, the memory can be stolen by MVS, and pages expected to be found in the HP will not be there. These are HP read ‘misses’, and are reflected in the system statistics records.
The critical, and now adjustable, thresholds have already been covered. However, some reenforcement is always useful. When adjusting thresholds, it is vital to understand what they mean, and the potential impacts of changes. Adjusting them incorrectly will certainly hurt performance. The hiperpool threshold, HPSEQT, determines how much (if any) sequentially accessed data and data read in using parallel sequential access will be cached in the HP. This should be carefully evaluated to determine if the pages will be re-referenced in the near term. If not, then this should be set to ZERO. Unless a VP is dedicated to scanned objects with frequently re-referenced pages, it is not beneficial to allow sequentially accessed data to migrate to a HP.
Buffer Pool Hit Ratios:
Calculating a correct system hit ratio is vital for performance analysis, and tracking performance over time. IBM has a correct formula in the V3 administration guide in chapter 7. The Getpage/RIO ratio, usually shown as an ‘efficiency’ ratio by online monitors is not meaningful for tracking either system or application performance. What is a good number for a GP/RIO ratio?? 5:1, 10:1, 50:1?? Obviously, the higher the better, but the numbers are not meaningful. DB2 V3 provides the ability to track the system hit ratio at the application accounting record level, by giving us a new field – Asynchronous Pages Read…the pages actually read in by prefetch type activity. The correct system hit ratio can be calculated using the following formula:
(Getpages-(SIO+PfPgs+LpfPgs+DynPfPgs))/Getpages * 100
Or
((Getpages – PagesRead)/Getpages) * 100
SIO = Synchronous Reads
Gp = Get Page Requests
PfPgs = Pages Read by Prefetch
LpfPgs = Pages Read by List Prefetch
DynPfPgs= Pages Read by Dynamic Prefetch
When using hiperpools, there are three other hit ratios that should be calculated and tracked to monitor the effectiveness of the hiperpool implementation, and we also want to track a second variation of the virtual pool hit ratio that also subtracts hiperpool hits. The first hiperpool method tracks the total percentage of pages found in the hiperpool, and the second method tracks the percentage of actual page hits that were found in the hiperpool. When these ratios are low, hiperpools are providing little benefit, and the usage and placement of objects should be reevaluated.
VP Hit Ratio
(Getpages-HPReads-SyncReads-Asynch Reads)/Getpages
HP Hit Ratio – First Way
HP Reads/Getpages
This is the % of Pages found in HP, but is not too meaningful
HP Hit Ratio – Second Way
HP Reads/(Getpages – Synch Reads – Asynch Reads)
This is the % of BP Hits found in HP
HP Effectiveness Ratio – Third Way
Pages Read from the HP/Pages Written to the HP
This is the effectiveness (benefit) ratio, and is the most meaningful
These ratios give us the ability to measure the efficiency of each pool resource. Even considering that the movement of a page from a HP to a VP is only 35 mcs, it is still more efficient to find the page in the VP.
Remember that ‘current active’ buffers does not mean the number of pages used or containing data. This is the number of buffers that are ‘not available’ or locked. All buffers in a pool always contain data when DB2 is functioning.
DB2 V3 provides buffer pool size information in the statistics record, and also produces an IFCID 202 record containing the Dynamic Zparm information at every statistics interval. Incidentally, it is better to produce statistics records at 15 minute intervals than the default 30 minutes. It provides a better level of granularity than 30 minutes without impacting performance, and also puts the data into the same measurement (elapsed) time frame as normal RMF data at most installations (although DB2 cannot be time synchronized the way RMF can).
Buffer Pool ——0–
Curr_Active………….51
Read Hit %……….. 7.89 **
VPOOL Alloc………. 9000
Exp/Con………………… 0
HPOOL Alloc………….. 0
…# Backed Strg…….. 0
…Read Fail……….. 0
…Write Fail……….. 0
GetPage…Total…. 1.061M
……….Seq…… 848511
……….Random… 212508
SyncRead Seq…….. 60914 *
………Random…. 179327
SeqPrefRead……… 25309
….Request……… 26123
….PagesRead…… 775415
….Dis NoBf…………….. 0
….Dis NoEn…………….. 0
WKFAbort…………………… 0
LstPrefRead…………….. 286
….Request……………. 249
….PagesRead………… 3739
DynPrefRead………….. 607
……Request………….. 626
……PagesRead……. 18815
DWHorThreshold………….. 1 *
DWVerThreshold…………. 19 **
DM Threshold…………….. 0
SynHPool..Read…………… 0
……….Write………….. 0
AsynHPool Read…………… 0
……….Write………….. 0
…DAMoverReadS………….. 0
……….ReadF………….. 0
Take special note of the ‘Synch Reads Seq’ field. First, there will almost always be some counts here because prefetch issues one synch I/O when it starts to run. However, large counts here, especially when coupled with low or ‘negative’ hit ratios indicate a serious performance problem. Pages read into the pool using prefetch can be released (or thrown out) by other prefetch activity before an application can get to them for processing. When this happens, they are read back in using synchronous IOs…and increment this counter. This has a serious performance impact on the elapsed time for the requesting, and most other, applications. This is most likely to happen in three (but not only) situations: when the processor is too busy (> 95%), when the application MVS dispatching priority is too low, or when the processor is not very busy and several large scan jobs execute concurrently.
As previously mentioned, we can calculate the hit ratio at the application level because of the new instrumentation. Also note the HP information that is available at this level.
Hit Ratio = (GP-PagesRd)/GP
BuffPool —0– —-1– —–2–
Get Page……..4……851…….22
Updates………2………0……..0
Lst Pref……….0………0……..0
Seq Pref……..0……..24……..0
Dyn Pref……..0………0……..0
PgsRdAsy……0……143……..0
SyncRead……2………6……..0
…..Write……..0………0………0
HplWrite…….0………0………0
…. Fail………..0………0………0
Hpl Read…….0……….0……..0
……Fail……….0……….0……..0
…..PgsRd……0……….0……..0
These application statistics indicate an 82.7% system hit ratio. The Class 3 I/O wait counters will show how much elapsed time was lost waiting for the synchronous I/O to complete, and whether the application had to wait for the prefetched pages to be brought into the buffer pool.
I/O Performance Relationships:
The elapsed time to retrieve a required 4K page varies considerably depending on where it is coming from:
.028 Sec. 3380
.020 Sec. 3390
.004-6 Sec. Cache, Solid State Device
.000035 Sec. HiperPool (100+ Times Faster)
These elapsed times for the 3380 and 3390 are quite generous and more closely approximate upper acceptable limits rather than the optimal times that are 20 and 16 Ms respectively.
Most installations still have poor overall DASD performance that impacts the online applications. Some of the primary causes are lack of staff time to properly place objects to reduce contention, and the ever larger capacity devices…so there are fewer physical devices to spread the objects and I/O workload across.
Buffer Pool tuning usually produces substantial application performance improvements, even when the pools are not large. Pool size alone usually provides some improvement; however, the largest payback comes from a combination of object placement and pool sizing.
DBM1 Memory Requirements and MVS Paging:
Increasing the size of the DBM1 address space beyond the capacity of Central Storage (as an overall consumption of all address spaces) will increase the MVS system paging rate. Even without paging to DASD (Death), this will impact application performance and response times. This appears as ‘MVS Overhead’, or unaccounted time, in the Class 2 elapsed times after all Class 3 wait times are subtracted. A good MVS overhead range for online transactions is approximately 1.5 or less, TSO should usually be in the 5-7 range, and Batch may range from 5 – 20 (with 10 as a good number) depending on workload mix and processor busy rate.
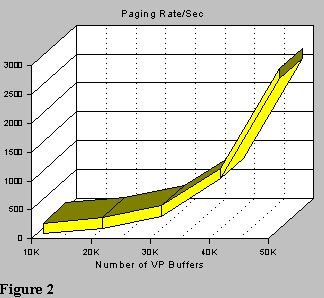
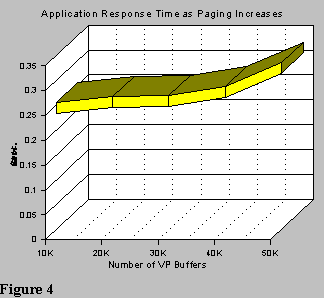
As the MVS paging rate increased, as shown in Figure 2, for this environment, the application performance degraded as shown in Figure 4. This can occur even while the system hit ratio increases. However, you will see increased pagins for read and write indicated in the statistics reports for each buffer pool. These should be used to obtain a paging rate per second for the buffer pools. While this may certainly indicate a problem, the overall paging rate for the entire DBM1 address space will be noticeably higher, and you can only obtain this from an online MVS monitor or RMF reports.
DB2 V3 provides counters in the statistics records indicating the number of times a requested pool page had to paged in for a read or write access. These should be monitored and tracked over time and compared to application performance. These paging counts are for the pools only, and do not include any paging activity for the rest of the address space. The counters should be added together for all the pools, and divided by the number of seconds in the statistics interval. The overall paging rate for the address space may be several to many times the rate per second of the pools alone, even though they are the major consumer of memory.
The Benefit of Using HiperPools:
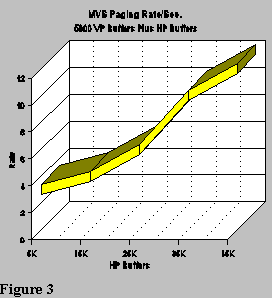
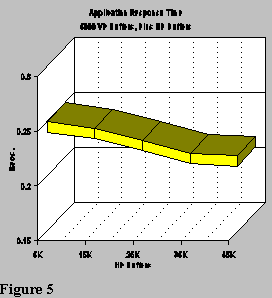
When the VP buffers are reduced, and the total pool resource is increased by using HP buffers, the paging rate can be kept quite low, as shown in Figure 3, and application performance improved as shown in Figure 5. However, over allocating HP buffers (hiperspace resources) eventually will hurt the overall MVS environment if adequate expanded storage isn’t available. Expanded storage is also a system resource, and many other address spaces need substantial amounts of this memory; even if it is only used for normal paging.
Using the HP to increase the memory hit ratio for data improves application performance, while not impacting the system wide MVS paging rate.
Pool Sizing and Object Placement:
Now let’s step beyond basic tracking of hit ratios and determine what data is necessary to properly distribute the objects across multiple pools, and how we approach pool sizing. Just throwing memory at the environment may eventually provide the desired application response times. However, this usually wastes large amounts of memory, and memory is NOT an inexpensive resource.
Since we are primarily concerned with READ performance, as it affects application response time, we need three IFCIDs: 198, 6, and 7. If we are also concerned with write activity, we should add the 8, 9, and 10 records. SMF is not a good destination for this type of trace data. DB2s usage of SMF is rather inefficient as a starting point, and SMF is used very heavily by MVS, CICS, and other application and system software. Therefore, it is easy to flood the buffers and lose data. Other facilities use SMF data as input, such as MICS and MXG. This may cause these jobs to run out of work space and abend. The other common alternative, GTF, is an MVS system level facility. If you have never used it, then forget about it. It has its own syntax, has to be started either from the MVS console or by a system programmer, and there can be only one GTF trace active in the MVS complex; therefore, if anyone else is using it, you can’t start it when you when to capture the DB2 performance records. Additionally, it is quite expensive to run when the volume of trace output is high. The last alternative, the IFI (Instrumentation Facility Interface) is a standard DB2 supported facility for getting data from the operating DB2 system. It requires writing some code, but is not difficult to access and use. By using the IFI interface, and writing to a dataset, the standard and instrumentation headers can be thrown away. This reduces the amount of data written by 200 bytes. The actual data from the records we need is quite short as you will see.
Trace Records:
7280+QW0198 DSECT
7282+QW0198DB DS H DATABASE ID
7283+QW0198OB DS H PAGESET OBID
7284+QW0198BP DS X BUFFERPOOL ID
7285+QW0198FC DS C FUNCTION CODE
7287+QW0198GP EQU C’G’ GET PAGE REQUEST
7288+QW0198SW EQU C’S’ SET WRITE INTENT
7289+QW0198RP EQU C’R’ RELEASE PAGE
7291+QW0198PS DS C PAGE STATUS IN POOL
7292+* APPLICABLE ONLY WHEN QW0198FC= ‘G’
7293+* QW0198PS=X’00’ WHEN QW0198FC=’S’ OR ‘R’
7295+QW0198H EQU C’H’ PAGE HIT IN BUFFERPOOL
7296+QW0198M EQU C’M’PAGE MISSED IN BUFFERPOOL
7297+QW0198N EQU C’N’ NOREAD REQUEST
7299+QW0198AT DS C ACCESS TYPE – QW1098AT IS
7300+* NOT APPLICABLE WHEN QW0198FC=’S’
7301+* QW0198AT = X’00’ WHEN QW0198FC = ‘S’
7302+**………QW0198AT CONSTANTS……….**
7303+QW0198SQ EQU C’S’SEQUENTIAL ACCES(GET PAGE)
7304+QW0198RN EQU C’R’ RANDOM ACCESS (GET PAGE)
7305+QW0198RL EQU C’L’ RIDLIST ACCES (GET PAGE)
7306+QW0198SR EQU C’N’ STD REQ (RELEASE PAGE)
7307+QW0198DR EQU C’D’ DESTRUCTIVE REQUEST (RELEASE PAGE)
7308+QW0198MR EQU C’M’ MRU SCHEME APPLIED (RELEASE PAGE)
7310+QW0198PN DS F PAGE NUMBER
7312+QW0198AC DS A ACE ADDRESS
The 198 records provide most of the base access information we need, with the exception of Dynamic Prefetch activity. However, it doesn’t tell us about read activity – how many pages were actually brought in by a prefetch read.
It is quite important to understand that the first getpage (GP) for a prefetched block could be ‘miss’, but the next 31 will absolutely be hits. This creates, at worst, an application hit ratio of 97%. It also doesn’t tell us how long the application might have waited for the prefetch to complete. For our purposes in this presentation we are not concerned with I/O wait or elapsed times, although these can easily be calculated from the 6 & 7 records using the time stamps.
Note the DBID and OBID in this record and in the next two records. These must be translated to a NAME for it to make sense. Therefore, we also need a ‘105’ trace record, or must query the catalog to map the trace records to a useful object name.
The IFCID 6 record shows us the type of physical read that takes place, and adds the Dynamic Prefetch information. The header (not shown) contains a time stamp that can be used together with the 7 record to get elapsed time.
836+*/* IFC ID 0006 FOR RMID 10 RECORDS THE ID OF THE DATA SET BEFORE
837+*/* A READ I/O OPERATION
840+QW0006 DSECT IFCID(QWHS0006)
841+QW0006DB DS XL2 DATABASE ID (DBID)
842+QW0006OB DS XL2 PAGESET OBID
843+QW0006BP DS F BUFFER POOL ID (0-49, 80-89)
845+QW0006PN DS XL3 FIRST PAGE NUMBER TO READ
846+QW0006F DS C FLAG FOR TYPE OF READ
847+QW0006FS EQU C’S’ SEQUENTIAL PREFETCH REQ
848+QW0006FL EQU C’L’ LIST PREFETCH REQUEST
849+QW0006FD EQU C’D’ DYNAMIC SEQ PREF REQ
850+QW0006FR EQU C’R’ READ REQUEST
851+QW0006AC DS F ACE TOKEN OF REQUESTOR
The IFCID 7 record now must be matched with the 6 record, and shows how many pages were actually read into the bufferpool by the read request. Synchronous I/O is obvious at one page. However, sequential, list, and dynamic prefetch may physically read anywhere from one through 32 pages into the pool….only those pages in the requested range that were not in the pool.
The 6 & 7 records also contain an ACE (Agent Control Element) that can be matched to a user address space to determine the planname and/or authid. For prefetch, there are two ACEs involved, the actual requestor, and the ACE of the Database Manager Address Space.
860+QW0007 DSECT IFCID(QWHS0007)
861+QW0007MM DS F MEDIA MANAGER RETURN CODE -0 SUCCESSFUL
862+QW0007DB DS XL2 DATABASE ID (DBID)
863+QW0007OB DS XL2 PAGESET OBID
864+QW0007AC DS F ACE TOKEN OF ACTUAL REQ.
865+* THIS MAY DIFFER FROM THE ACE TOKEN IN THE STANDARD
866+* HEADER FOR THIS RECORD, EG IN SEQUENTIAL PREFETCH.
867+QW0007NP DS H NUMBER OF PAGES READ
Based on the 198 records in a collected set of trace data we obtain the following statistics, that show a 69.6 % overall pool hit ratio. This, however, is the application hit ratio because it doesn’t consider the number of pages read by prefetch functions. While the application hit ratio is the real measure of application I/O delay, the system hit ratio is equally, and many times more important, since we are tuning a ‘Global Resource’ – a system buffer pool.
Note the wide difference between the application hit ratio and the system hit ratio in the following data:
Statistics for Buffer Pool: BP0
Buffer size is………………………4K
Number of VP Buffers is…………..30,000
VP sequential threshold is…………..80%
Number of HP BUffers is……………….0
HP sequential threshold is…………..80%
Hiper Space Castout is………………..Y
Number of GetP……………….1,829,682
Number of No_Reads……………….1,834 0.1% of GetP
Number of Sequential Access……1,108,786 60.6% of GetP
Number of Random Access…………709,915 38.8% of GetP
Number of RID_List……………….9,147 0.5% of GetP
Number of Random Misses…………551,887 12.5 Misses per Second
Number of Misses (others)…………4,775 1.3 Misses per Second
Number of Hits……………….1,273,020 69.6% of GetP (Appl. HIT %)
Number of Pages Read………….1,129,246 65.1 Pages Read per Second
Number of Sync. Pages Read……..551,874 48.9% of Pages Read
Number of SPref. Pages Read……..410,431 36.3% of Pages Read
Number of LPref. Pages Read…………214 0.0% of Pages Read
Number of DPref. Pages Read……..166,738 14.8% of Pages Read
Number of Start I/Os……………605,661 34.9 Start I/Os per Second
Number of Sync. Start I/Os……..551,877 91.1% of Start I/Os
Number of SPref. Start I/Os………36,064 6.0% of Start I/Os
Number of LPref. Start I/Os…………214 0.0% of Start I/Os
Number of DPref. Start I/Os………17,526 2.9% of Start I/Os
System HIT RATIO –> 34.5 % <-- (Get pages - Pages read) / Get pages By utilizing the 6 & 7 read records, we obtain the true system hit ratio. While the application hit ratio is important because it indicates application performance, this is across all application plans and can hide application performance problems caused by synchronous I/O wait times. These types of statistics can easily be produced by writing some code...using SAS, PL/1, Assembler, or REXX. After the overall pool statistics, we want the same type of information for each object within a pool. The objects should be sorted in order of decreasing getpage activity, because we want to see the most heavily accessed objects first. The V3 Buffer Pool displays can produce somewhat similar information, but can't order it. Therefore, the most heavily accessed objects might be at the bottom of thousands of lines, or might be truncated off the report. Likewise, it will not work to try groups of display commands. At the detail level, they are incremental since the last display...and you need all information from the same time span and duration for the results to be meaningful. ** Statistics for Table Space.......DSNDB06.SYSDBASE Number of GetP......................944,773 51.6% of Total BP GetP Number of No_Reads........................0 0.0% of GetP Number of Sequential Access.........352,964 37.4% of GetP Number of Random Access.............591,047 62.6% of GetP Number of RID_List......................772 0.1% of GetP Number of Random Misses.............401,831 23.2 Misses per Second Number of Misses (others)............40,146 2.3 Misses per Second Number of Hits......................502,805 53.2% of GetP (Application HIT RATIO) Number of Pages Read................764,323 44.0 Pages Read per Second Number of Sync. Pages Read.........430,577 56.3% of Pages Read Number of SPref. Pages Read.........189,764 24.8% of Pages Read Number of LPref. Pages Read.............214 0.0% of Pages Read Number of DPref. Pages Read.........143,783 18.8% of Pages Read Number of Start I/Os................467,018 26.9 Start I/Os per Second Number of Sync. Start I/Os.........430,579 92.2% of Start I/Os Number of SPref. Start I/Os..........20,773 4.4% of Start I/Os Number of LPref. Start I/Os.............214 0.0% of Start I/Os Number of DPref. Start I/Os..........15,465 3.3% of Start I/Os System HIT RATIO.......................19.1% <<<< Note Online monitors can collect the data, but cannot save and process enough of it for the types of meaningful statistical analysis and other processing we have in mind. Snapshot collections of a 'few minutes' are not generally useful unless the transaction workload and mix is very consistent...over a short period. Longer periods provide much better accuracy. Typically, a good quantity is more than two million getpage records (198s) for a V3 system...since almost half of these are 'release page' records. In reality three million plus is a better collection and provides the best consistency. Large environments can easily generate ten to fifty million getpage records per hour. What do we look for in the statistical analysis? We look for indexes and tablespaces with a high % of sequential access, or Sequentially Accessed Mostly (SAMO), and since we want to differentiate between large and small working sets we have SAMOS and SAMOL; and indexes and tablespaces that are Randomly Accessed Mostly (RAMO), and we also differentiate here, we have RAMOS and RAMOL. The end result of our analysis is to group similarly accessed objects together. The RAMOS, RAMOL, and SAMOS, SAMOL objects. Additionally, we must know specifically how they are accessed, and the average and maximum number of pages they had resident in a pool at any point during the collection. The average and maximum working sets are also very important, when grouping objects together. Is all right to group a tablespace that is accessed randomly, with a small maximum working set, with indexes with similar access patterns and working sets. Results of Simulation by Objects in Buffer Pool.......................BP0 Bpool GetP total..................................................................2,814,700 Results for Index.............................................................DB2ADM.ICST005B Object GetP total..........................................1,455,840 (51.7% of BP GetP) Bpool Size GetP used Num. of Hits Hit Ratio Avg. WSet Max. WSet 5,000 1,455,840 1,298,609 89.2 % 155 179 6,000 1,455,840 1,349,684 92.7 % 159 180 7,000 1,455,840 1,455,088 99.9 % 161 181 8,000 1,455,840 1,455,230 100.0 % 162 181 Results for Table Space...................................................DB2PAI.PORDQ01 Object GetP total..............................................227,056 ( 8.1% of BP GetP) Bpool Size GetP used Num. of Hits Hit Ratio Avg. WSet Max. WSet 5,000 227,056 215,033 95.1 % 918 4,011 6,000 227,056 220,372 97.0 % 1,120 4,804 7,000 227,056 220,539 97.1 % 1,317 5,606 8,000 227,056 220,558 97.1 % 1,519 6,439 These two objects do not belong together in the same pool. The index is a nicely behaved RAMOS, and the tablespace is a poorly behaved SAMOL...because the maximum working set continually expands to use the entire prefetch LRU queue (default 80% of the pool). The total number of pages in the pool can exceed the 80% sequential threshold since some pages are also read randomly. Pool tuning, sizing, and object placement is not a guessing game. It takes a large effort to get everything done properly, and once done, it must be monitored frequently and adjustments made. New applications come into the system, SQL is re-coded and access paths change, databases grow, etc. Effective pool tuning, sizing, and object placement provides significant performance improvements...for the applications, for the DB2 system, for the DASD subsystem, and for the entire MVS complex. Now we get to the difficult part...attempting to simulate, or estimate, pool and object performance as sizes are changed and objects are moved around. Simulations are extremely difficult to write, and require a lot of formula 'tweaking' to get correct results. However, it's the only way to ever get things done correctly (optimally) since you can't play dangerous and time consuming games with your production environment. The simulation results above indicate increasing pool hit ratios as the size is increased. From these figures, 7,000 buffers are probably optimal unless you have memory to spare and wish to pick up that last .8%. The simulation report combines both simulation techniques and statistical analysis to provide useful information at the object level. The results from a simulation run must be analyzed in conjunction with a Statistical analysis that shows rates and type of access for each object. The Index object is 'well behaved', meaning the average and maximum number of pages in the pool (Working Set or WkSet) are not large, the maximum is not multiples of the average. and they don't increase greatly as the pool size increases. Note the increase in hit ratio as the pool increases from 5000 to 7000 buffers, and that the Index had 51.7% of the total getpage activity. On the other hand, look at the difference between the Avg and Max WkSet for the tablespace, and the Max ranges from 75-80% of the total pool size. These must be separated into different pools to optimize the access through the index since this usually has the greatest impact on normal well behaved online transactions. Average Page Residency Time is quite easy to calculate on a gross basis by using the following formula for both the pool and for the objects: ((Getpages - PagesRd)/Getpages) * Time This ignores data hot spots, but provides a general idea how long pages tend to remain in the pool. At the same time, if most of the getpages are for the hot pages, this becomes quite relevant. The important point to remember, is that we want a page to be in the pool when the getpage is issued. Technically, for our purposes, a page could live in a pool for ten minutes without being referenced, and be thrown out just before it is needed...this is not of any value and affects the residency time as a 'miss', or zero for that page. Clustering analysis of actual page numbers provides the true reference patterns, and at the same time can provide the 'range of pages' in the average and maximum working sets of pages in the pool. Occasionally people from an installation say their DB2 system doesn't have any performance problems. Well, every system has performance problems. Of course the critical factor is the 'magnitude' of the problems, and the effort required to correct them. Sometimes (but rarely) the problems are not significant, while the effort will be very large...therefore they might not be worth fixing. When somebody says they don't have any DB2 performance problems, they either don't know where or how to look for them, or simply haven't taken the time to look. It would be rare and extremely unlikely that an installation using only one pool is getting good performance. This could be possible if almost all of the workload is random, and all the objects have small working sets....but this has a very low probability. Perhaps the fact that IBM gave us 60 Pools with version 3 implies that using multiple pools can optimize performance. [/av_textblock] [/av_one_full] [/av_section] [av_one_full first min_height='' vertical_alignment='' space='' row_boxshadow='' row_boxshadow_color='' row_boxshadow_width='10' custom_margin='' margin='0px' mobile_breaking='' border='' border_color='' radius='0px' padding='0px' column_boxshadow='' column_boxshadow_color='' column_boxshadow_width='10' background='bg_color' background_color='' background_gradient_color1='' background_gradient_color2='' background_gradient_direction='vertical' src='' background_position='top left' background_repeat='no-repeat' highlight='' highlight_size='' animation='' link='' linktarget='' link_hover='' title_attr='' alt_attr='' mobile_display='' id='' custom_class='' aria_label='' av_uid='av-h0jul'] [av_heading heading='Case Study 1:' tag='h3' link='' link_target='' style='blockquote modern-quote' size='' subheading_active='' subheading_size='' margin='' padding='10' icon_padding='10' color='custom-color-heading' custom_font='#f89730' icon_color='' show_icon='' icon='ue800' font='' icon_size='' custom_class='joelres' id='' admin_preview_bg='' av-desktop-hide='' av-medium-hide='' av-small-hide='' av-mini-hide='' av-medium-font-size-title='' av-small-font-size-title='' av-mini-font-size-title='' av-medium-font-size='' av-small-font-size='' av-mini-font-size='' av-medium-font-size-1='' av-small-font-size-1='' av-mini-font-size-1='' av_uid='av-9fkd9'][/av_heading] [av_textblock size='' av-medium-font-size='' av-small-font-size='' av-mini-font-size='' font_color='' color='' id='' custom_class='' av_uid='av-kl0oeee9' admin_preview_bg=''] These are initial performance results from one installation, before tuning, that said they had good performance, and their buffer pool hit ratios were great. The initial situation and the user perspective were:
- One Large Pool…..60,000 Buffers
- We don’t have any Performance Problems….
- Nobody is Complaining about Poor Performance…
- Our bufferpool Performance is Great!!!
 The system actually showed:
The system actually showed:
- Getpage/RIO averaged between 50 -70:1
- Actual HIT RATIO averaged between 45 – 55%!!!! POOOOR!!!
- Overall, Transactions Averaged > than 1 Second of Class 2 Elapsed
The average I/O Wait per Transaction was between .4 – .5 Seconds
- This I/O Wait alone indicates a problem…..
Just because nobody complains, does not mean things are running well.
The First Tuning Approach:
The first shotgun tuning effort left 15,000 buffers in BP0 for the catalog, directory, and tablespaces, placed 20,000 buffers into BP1 for the indexes, and 20,000 in BP2 for the DSNDB07 sort/work files.
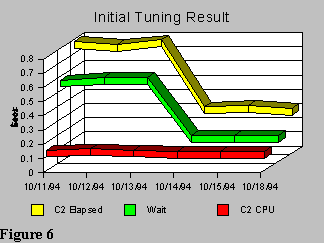
This initial tuning effort showed dramatic performance improvements as illustrated in Figure 6, while using Less Memory.
 Actually, later tuning exercises have shown it’s usually better to leave the Indexes in BP0 (prior to V3) with the catalog and directory…since indexes (should be) are usually accessed randomly. The initial tuning improved application response times, used less memory, and reduced the CPU busy rate. The CPU reduction is primarily attributable to the reduced number of concurrently active threads, with some small contribution from a reduced I/O workload.
Actually, later tuning exercises have shown it’s usually better to leave the Indexes in BP0 (prior to V3) with the catalog and directory…since indexes (should be) are usually accessed randomly. The initial tuning improved application response times, used less memory, and reduced the CPU busy rate. The CPU reduction is primarily attributable to the reduced number of concurrently active threads, with some small contribution from a reduced I/O workload.
Now we got serious, analyzed the object usage, and moved objects into different pools. Since this was a V2.3 system, we were certainly limited by having only three 4K pools.
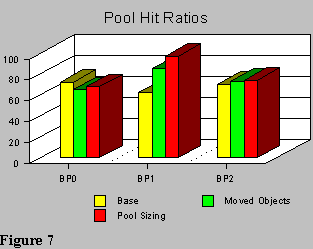
Figure 7 shows the results of three stages of pool tuning. The base pool hit ratios after the initial ‘shotgun’ tuning approach; stage 2 as objects were moved, the hit ratio on BP1 increased significantly. The hit ratio dropped for BP0 because an object that had a ‘high’ hit ratio was moved out of the pool. The last scenario shows hit ratios improved again for BP0 and BP1 after the final pool sizing. This took back 10 of the 20 Megabytes initially saved, providing a final saving of 10 Megabytes, with substantially improved application performance.
Two reasonable V3 pool usage scenarios. Most installations should be able to optimize performance with five to eight pools. While some installations might ultimately use a few more pools, too many pools mean a lot more administrative work, and usually waste memory..
Example 1
BP0 Catalog & Directory
BP1 Indexes Accessed Randomly – RAMOS
BP2 Indexes Accessed Sequentially – SAMOL
BP3 Tablespaces Accessed Sequentially – SAMOL
BP4 Tablespaces Accessed Randomly – RAMOS
BP5 Tablespaces Accessed Randomly – RAMOL
BP6 DSNDB07
Example 2
BP0 Catalog, Directory, Random Indexes
(Small WkSet) – RAMOS
BP1 Indexes Accessed Randomly
(Med to Lg WkSet) RAMOL
BP2 Indexes Accessed Sequentially SAMOS,
SAMOL
BP3 Tablespaces Accessed Sequentially SAMOS, SAMOL
BP4 Tablespaces Accessed Randomly RAMOS
BP5 Tablespaces Accessed Randomly RAMOL
BP6 Tablespaces having Transient Pages
BP7 DSNDB07
Upper Limit?:
While some large systems many need more than five to eight, ten to twelve might be an upper limit on effective pool and object tuning. Remember, the pools are a system resource. While segregating them on an application basis might be nice for the application, it is unlikely this approach will provide the most efficient usage of pool and memory resources. Unless there is a specific reason to uniquely segregate some objects, using too many pools simply wastes memory and increases the effort of performance tracking and analysis.
Summary:
There are innumerable opportunities for improving DB2 system and application performance. While physical design and SQL tuning will almost always provide the greatest paybacks, these efforts are usually work intensive and sometimes difficult to implement in a busy production environment. The next greatest opportunity for improving application response time, and saving CPU cycles is buffer pool tuning. Commercially available software can make this a true scientific process instead of a guessing game and significantly reduce the time necessary to properly size and tune the buffer pools.
- Let’s tune those systems!
- Improve Application Response Times!
- Optimize DB2s usage of Memory!
- Use an Automated Operator Facility to resize pools and/or adjust thresholds for different workloads, such as your daily batch cycle.
The Future:
The next performance challenge is the parallel Sysplex and DB2 Data Sharing.
The Author:
Joel Goldstein is an internationally acknowledged performance expert, consultant, and instructor. He has more than 30 years of experience, and has been directly involved with the performance management and capacity planning of online database systems for more than 20 years. Joel has more than ten years of experience addressing DB2 design, performance, and capacity planning issues, and has assisted many large national and international clients with their systems and applications. He is a frequent speaker at DB2 user groups and Computer Measurement Group meetings throughout North America, Europe, and the Far East. In addition to publishing more than two dozen articles on DB2 performance issues, he is also a technical editor for Enterprise Systems Journal, The Relational Journal, and was the database editor for CMG Transactions. Joel is a Director of the Northeast Region CMG, is a director of TRIDEX, has been on the CMG national program committee for five years and has been a member of the North American IDUG conference committee for three years.
He is president of Responsive Systems, a firm specializing in strategic planning, capacity planning, and performance tuning of online database systems